1. 概述
KNN算法可以说是最简单的分类算法之一,同时,它也是最常用的分类算法之一,该算法是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类,就把该输入实例分类到这个类中,类似于现实生活中少数服从多数的思想。
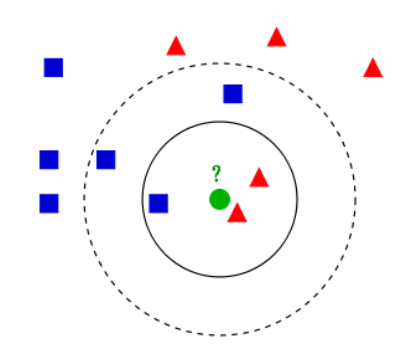
下面通过一个简单的例子说明一下:如下图,绿色圆要被决定赋予哪个类,是红色三角形还是蓝色四方形?如果K=3,由于红色三角形所占比例为2/3,绿色圆将被赋予红色三角形那个类,如果K=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。
2. 算法流程
在训练集中数据和标签已知的情况下,输入测试数据,将测试数据的特征与训练集中对应的特征进行相互比较,找到训练集中与之最为相似的前K个数据,则该测试数据对应的类别就是K个数据中出现次数最多的那个分类,其算法的描述为:
- 计算已知类别数据集中的点与当前点之间的距离
- 按距离递增次序排序
- 选取与当前点距离最小的k个点
- 统计前k个点所在的类别出现的频率
- 返回前k个点出现频率最高的类别作为当前点的预测分类
KNN取距离度量的方式:
距离计算:
要度量空间中点距离的话,有好几种度量方式,比如常见的曼哈顿距离计算,欧式距离计算等等。不过通常KNN算法中使用的是欧式距离,这里只是简单说一下,拿二维平面为例,,二维空间两个点的欧式距离计算公式如下:
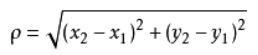
拓展到多维空间,则公式变成这样:
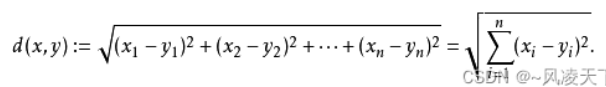
KNN算法最简单粗暴的就是将预测点与所有点距离进行计算,然后保存并排序,选出前面K个值看看哪些类别比较多。
K值选择:
在实际应用中,K值一般取一个比较小的数值,例如采用交叉验证法(简单来说,就是一部分样本做训练集,一部分做测试集)来选择最优的K值。
如果选择较小的K值,就相当于用较小的领域中的训练实例进行预测,“学习”近似误差会减小,只有与输入实例较近或相似的训练实例才会对预测结果起作用,与此同时带来的问题是“学习”的估计误差会增大,换句话说,K值的减小就意味着整体模型变得复杂,容易发生过拟合;
如果选择较大的K值,就相当于用较大领域中的训练实例进行预测,其优点是可以减少学习的估计误差,但缺点是学习的近似误差会增大。这时候,与输入实例较远(不相似的)训练实例也会对预测器作用,使预测发生错误,且K值的增大就意味着整体的模型变得简单。
K=N,则完全不足取,因为此时无论输入实例是什么,都只是简单的预测它属于在训练实例中最多的类,模型过于简单,忽略了训练实例中大量有用信息。
3. KNN算法的特点与优缺点
3.1 特点
KNN是一种非参的,惰性的算法模型。
非参: 模型不会对数据做出任何的假设,与之相对的是线性回归(我们总会假设线性回归是一条直线)。也就是说KNN建立的模型结构是根据数据来决定的。
惰性: 同样是分类算法,逻辑回归需要先对数据进行大量训练,最后才会得到一个算法模型。而KNN算法却不需要,它没有明确的训练数据的过程,或者说这个过程很快。
3.2 KNN算法的优势和劣势
优点:
- KNN算法简洁明了,模型训练时间快
- 预测效果好,对异常值不敏感
缺点:
- 对内存要求较高,因为该算法存储了所有训练数据
- 预测阶段可能很慢
- 对不相关的功能和数据规模敏感
4. KNN算法的应用
开发样例: https://github.com/Magi2B0y/KNN-algorithm-application
在实现为用户推荐相似好友、生成每首歌的相似音乐和为用户提供推荐音乐三个功能上应用到了KNN算法
数据源: 数据库中所有用户的听歌记录
数据结果: 为所有用户生成相似好友,为每首歌生成相似歌曲,最后根据每首歌的相似歌曲和用户听歌记录来为用户提供推荐音乐
项目文件功能如下表:
| 文件名 | 功能 |
|---|---|
| main_function.py | 顺序执行以下py文件 |
| update_data_source.py | 读取数据库中需要的数据,作为模型训练的数据集,存储在dataset下 |
| other_user_recommend.py | 训练得到所有用户的相似用户 |
| user_listened_recommend.py | 将训练得到的相似音乐和用户听歌记录相结合,得到所有用户的音乐推荐 |
| insert_DB.py | 将结果集重新存入数据库 |
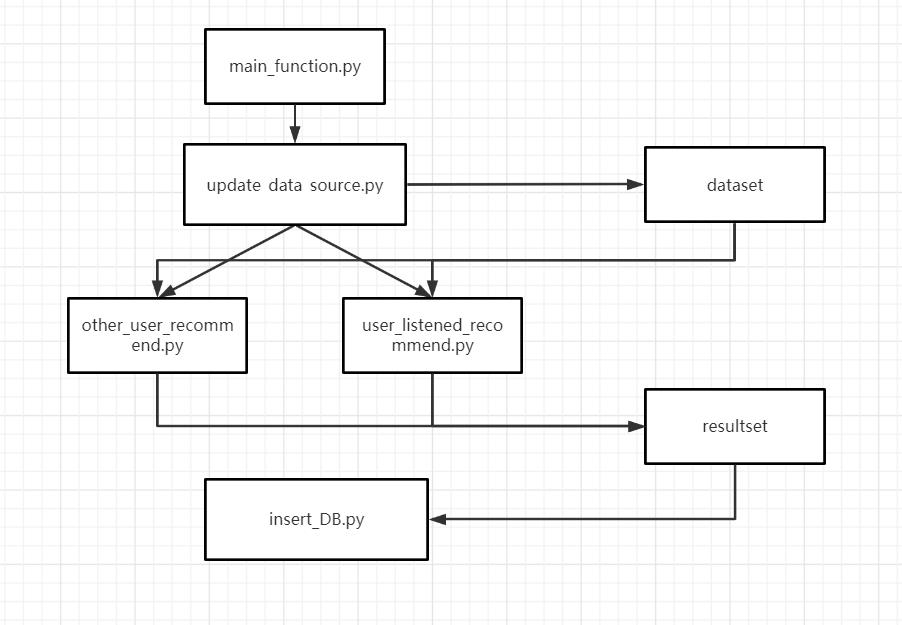
python文件的调用流程如下:
关键的模型训练部分代码如下:
1 | def get_trainset_algo(): |
输出结果集:
每首音乐的10首相似音乐:
为每位用户推荐的20首音乐:
为每位用户推荐的10位相似好友:

在文章最后,介绍一下github开源项目不同 license 的具体含义
| license | 含义 |
|---|---|
| Apache | 使用这个协议可以进行商用,可以对其修改、分发,但是要声明作者来源和你的修改以及协议。很多大型项目都使用这个协议,比如 tensorflow、puppeteer。 |
| MIT | 这是个人用得比较多的协议,因为比较宽松精简,只要声明版权和协议就可以了,可以商用、修改、复制、重新发布等操作。使用这个协议的就有vue、react等 |
| BSD | 这个和 MIT 协议类似,但未经事先明确书面许可,不得使用版权所有者的姓名或其贡献者的姓名来认可或推广从本软件衍生的产品,其它基本操作都可以使用。flask 用的就是这个协议。 |
| GNU | 可以私用也可以商用,但是必须声明来源,并且需要声明原有的协议,以及你的代码也必须开源出来。我们很熟悉的 Linux 就是采用这种协议。 |
| NO | 就是什么都不声明,但是并不意味着就可以乱来,这比声明了协议还严格。你可以使用、商用,但是你需要声明协议和来源,而且,你不能对代码进行修改、复制、再次发布。 |
| Eclipse | 这个协议允许你商用、复制、修改、再次发布等,需要声明来源和协议。像 java 中的 junit4 就是使用这个协议。 |
以下以一张图来简单概述协议之间的区别:
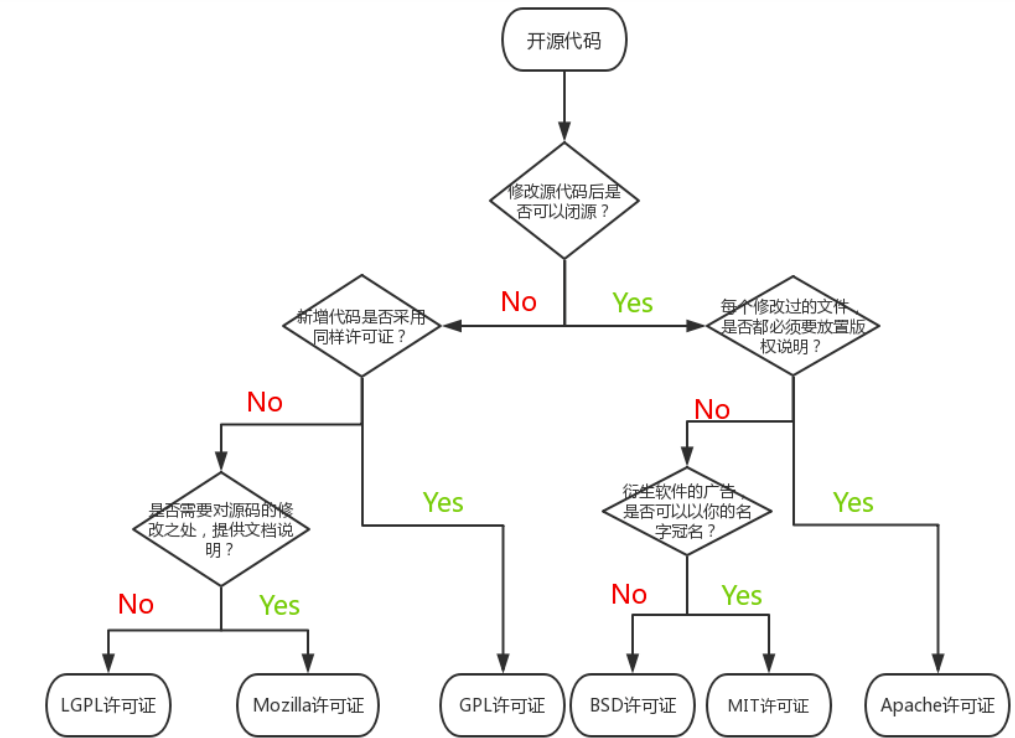
更加详细的说明请查看 https://opensource.org/licenses/alphabetical
ENDฅฅ